Risk Modeler 1.11 Release: Accelerating Access to Powerful Insights From the RMS U.S. Inland Flood HD Model
Meghan PurdyMay 09, 2019
The April release of Risk Modeler 1.11 marks a major milestone in both model science and software. For the first time at RMS, a complete high-definition (HD) model – the RMS U.S. Inland Flood (USFL) HD model with integrated storm surge, and an accompanying model validation workflow are now available to all users on the new platform. It also marks the release of exciting new capabilities including auditable exposure edits and data access via third-party business intelligence and database tools.
What is Different About Model Validation on Risk Modeler?
For the USFL model to produce detailed insights into risk, it must realistically simulate the interactions between antecedent environmental conditions, event clustering, exposures, and insurance contracts over tens of thousands of possible timelines. That requires a new financial engine, a more powerful model execution engine, and a purpose-built database to handle the processing of and metrics calculation against the vast amounts of data that an HD model produces. Although the current RiskLink solution can perform some of these tasks and processes well and efficiently, Risk Modeler was especially built for these new requirements.
In addition to simply running this next-generation model, Risk Modeler has several features to quickly surface insights into the model and ultimately allow users to make business decisions faster.
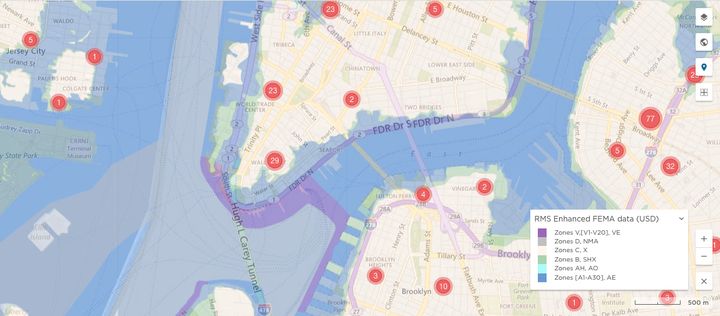
1) Integrated Maps and Analytics: Dashboards and maps help users analyze exposure alongside the results. For example, users can overlay their exposures and the FEMA flood zones on a map, then run accumulations to understand their exposed limit in each zone.
Image 1: FEMA flood zones overlaid on a map of a portfolio’s risk items.
Or users might quickly generate maps of their USFL Annual Average Loss (AAL) state-by-state inside the application, instead of exporting data to mapping tools such as ArcGIS, making the process more seamless, saving time, and reducing the chance of error.
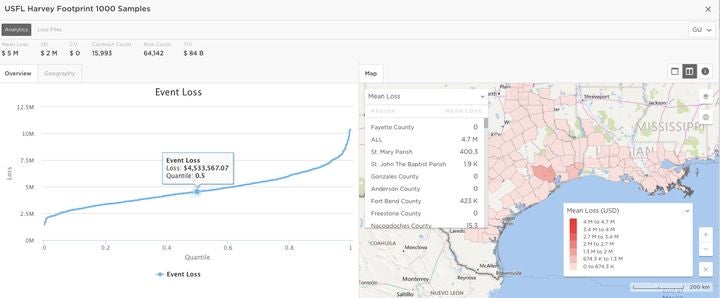
2) All Results From All Model Permutations: The RMS Platform is purpose-built for risk analytics, with swift read/write capabilities and a state-of-the-art model execution and analytics engine. This is especially critical for model validators, who must first generate large amounts of data before distilling insights from the output.
Image 2: Understanding the range of losses from the Harvey footprint by sampling a thousand times.
In RM 1.11, users can run all flavors of the model (Exceedance Probability – EP / scenario / historical / footprint; simulated / expected; with and without storm surge; and much more), test convergence with period count and sampling options, and produce metrics including location-level period loss tables (PLTs), intermediate hazard and damage, and more. These results can be downloaded, though users are encouraged to take advantage of the querying capabilities of the notebook, which is built on big data technology to execute queries quickly.
3) Contributory Metrics: Model validators can take advantage of powerful metrics in Risk Modeler to help them extract insights about their data faster.
In addition to the usual PLT, EP curves, and AAL, users can request contributory and correlation metrics in the notebook. Contributory metrics are much more powerful than AAL because they provide contribution of a segment to portfolio loss at key return periods — and it is those return period losses that drive capital requirements and reinsurance premiums.
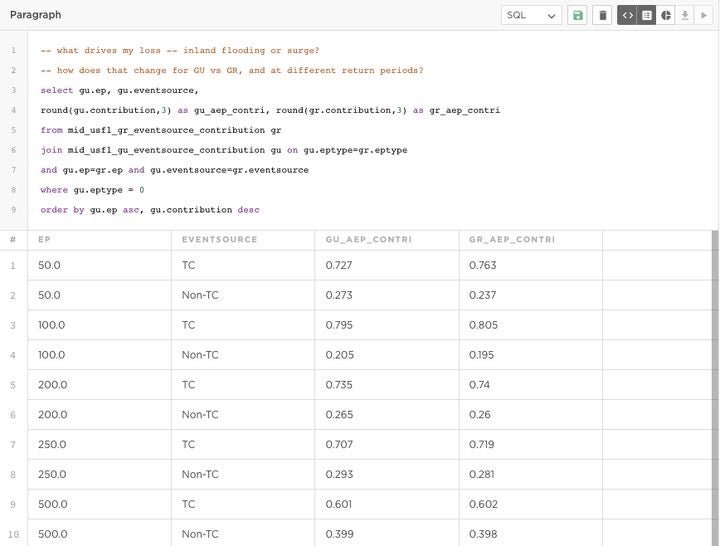
RM 1.11 also adds new levels of detail at which these metrics can be calculated: by river basin, FEMA flood zone, and flood source, i.e., tropical cyclone or non-tropical cyclone flood-driven, in addition to geographic and building attributes. Thus, model validators can understand how hurricanes contribute to, for example, their 50-year inland flood Occurrence Exceedance Probability (OEP) and how that changes as you move out on the EP curve.
Image 3: Querying the contribution of tropical cyclone and non-tropical cyclone-induced flood events to GU and GR loss at different return periods.
What Else is Available?
The RM 1.11 release includes several advancements that make the platform more open and flexible:
1) New Exposure Views: Understand and query contract terms and conditions.
2) Edits: Edit risk item attributes, save them as variations of existing portfolios, and track changes in an audit trail.
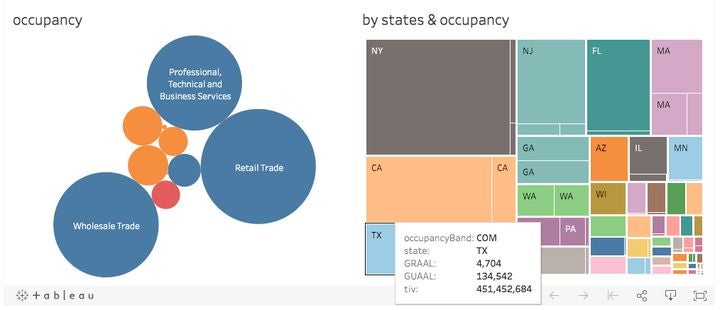
3) JDBC/ODBC Access: Use JDBC/ODBC connections to interact with exposure and results data from tools including Tableau, Excel, DbVisualizer, and Hive.
Image 4: Visualizing Total Insurable Value (TIV) using Tableau.
Edits and JDBC/ODBC access are being released as preview features in RM 1.11. Client feedback is a core tenet of our product development model. As such, we now showcase features earlier in our development cycle in order to gather and then incorporate customer feedback before the official launch. If you have feedback on these preview features, please contact us via your RMS account representative or leave feedback directly in the application via UserVoice.
These features are just the tip of the iceberg. At our Exceedance conference next week, we will cover these exciting features and provide a sneak peek of what’s to come. If you are attending, join the RMS Software track presentations or drop by the Expert Bar to hear more. Licensing clients can also see the full suite of capabilities on RMS Owl.
Share:
You May Also Like
November 11, 2013
Will it Blend? (…And Now What?)
In previous posts on multi-modeling, Claire Souch and I discussed the importance of validating models and the principles of model blending. Today we consider more practical issues: how do you blend, and how does it affect pricing, rollup, and loss investigation?
No approach to blending is superior. There are trade-offs between granularity of blending ratios allowed, ease of implementation, mathematical correctness, and downstream functionality. For this reason, several methods should be examined.
Hybrid Year Loss Table (YLT)
The years, events, and losses of a hybrid YLT are selected from source models in proportion to their assigned blending weights. For example, a 70/30 blend of two 10,000-year YLTs is composed of 7,000 years selected at random from Model A and 3,000 years selected at random from Model B.
Hybrid YLTs preserve whole years and events from their source models, and drilling down and rolling up still function. But the blending could have unexpected results, as users are working with YLTs instead of directly altering EP curves. Blending weights cannot vary by return period, which may be a requirement for some users.
Simple Blending
Simple blending produces a weighted average EP curve across the common frequencies or severities of source EP curves. Users might take a weighted average of the loss at each return period (severity blending) or a weighted average of the frequency of loss thresholds (frequency blending). Aspen has produced an excellent comparison of the pros and cons of blending frequencies vs. severities.
Simple blending is appealing because it is easy to use and understand. Any model with an EP curve can be used—it need not be event-based—and weights can vary by return period or loss threshold. It is also more intuitive: instead of modifying YLTs to change the resulting EP curve in a potentially unexpected way, users operate on the same base curves. Underwriters may prefer it because they can explicitly factor in their own experience at lower return periods.
While this is useful for considering multiple views at an aggregate level, the result is a dead end. Users can’t investigate loss drivers because a blended EP curve cannot be drilled into, and there is no YLT to roll up.
Scaled Baseline: Transfer Function
Finally, blending with a transfer function adjusts the baseline model’s YLT with the resulting EP curve in mind. Event losses are scaled so that the resulting EP curve looks more like the second model’s curve, to a degree specified by the user.
Unlike the hybrid YLT and simple blending methods, the baseline event set is maintained, and the new YLT and EP curve can be used downstream for pricing and roll-up. Blending weights can also vary by return period.
However, because it alters event losses, some drill-downs become meaningless. For example, say Model A’s 250-year PML for US hurricane is mostly driven by Florida, while Model B’s is mostly driven by Texas. If we adjust the Model A event losses so that its EP curve is closer to Model B’s, state-level breakouts will not be what either model intended.
Alternatives
Given the downstream complexities of blending, it may be preferable to adjust the baseline model to look more like an alternate model, without explicitly blending them. This could be a simple scaling of the baseline event losses, so that the pure premium matches loss experience or another model. Or with more sophisticated software, users could modify the timeline of simulated events, hazard outputs, or vulnerability curves to match experience or mimic components of other models.
Where does that leave us?
Over the past month, we’ve explored why and how we can develop a multi-model view of risk. Claire pointed out that the foundation to a multi-model approach first requires validation of the individual models. Then I discussed the motivations for weighting one model over another. Finally, we turned to how we might blend models, and discovered its good, bad, and ugly implications.
Multi-modeling can come in many forms: blending results, adjusting baseline models, or simply keeping tabs on other opinions. Whatever form you choose, we’re committed to building a complete set of tools to help you understand, take ownership of, and implement your view of risk.…
My colleague Claire Souch recently discussed the most important step in model blending: individual model validation. Once models are found suitable—capable of modeling the risks and contracts you underwrite, suited to your claims history and business operations, and well supported by good science and clear documentation—why might you blend their output?
Blending Theory
In climate modeling, the use of multiple models in “ensembles” is common. No single model provides the absolute truth, but individual models’ biases and eccentricities can be partly canceled out by blending their outputs.
This same logic has been applied to modeling catastrophe risk. As Alan Calder, Andrew Couper, and Joseph Lo of Aspen Re note, blending is most valid when there are “wide legitimate disagreements between modeling assumptions.” While blending can’t reduce the uncertainty from relying on a common limited historical dataset or the uncertainty associated with randomness, it can reduce the uncertainty from making different assumptions and using other input data.
Caution is necessary, however. The forecasting world benefits from many models that are widely accepted and adopted; by the law of large numbers, the error is reduced by blending. Conversely, in the catastrophe modeling world, fewer points of view are available and easily accessible. There is a greater risk of a blended view being skewed by an outlier, so users must validate models and choose their weights carefully.
Blending Weights
Users have four basic choices for using multiple valid models:
Blend models with equal weightings, without determining if unequal weights would be superior
Blend models with unequal weightings, with higher weights on models that match claims data better
Blend models with unequal weightings, with higher weights on models with individual components that are deemed more trustworthy
Use one model, optionally retaining other models for reference points
On the surface, equal weightings might seem like the least biased approach; the user is making no judgment as to which model is “better.” But reasoning out each model’s strengths is precisely what should occur in the validation process. If the models match claims data equally well and seem equally robust, equal weights are justified. However, blindly averaging losses does not automatically improve results, particularly with so few models available.
Users could determine weights based on the historical accuracy of the model. In weather forecasting, this is referred to as “hindcasting.” RMS’ medium-term rate model, for example, is actually a weighted average of thirteen scientific models, with higher weights given to models demonstrating more skill in forecasting the historical record.
Similarly, cat model users can compare the modeled loss from an event with the losses actually incurred. This requires detailed claims data and users with a strong statistical background, but does not require a deep understanding of the models. An event-by-event approach can find weaknesses in the hazard and vulnerability modules. However, even longstanding companies lack a long history of reliable, detailed claims data to test a model’s event set and frequencies.
Weights could also differ because of the perceived strengths of model components. Using modelers’ published methodologies and model runs on reference exposures, expert users can score individual model components and aggregate them to score the model’s trustworthiness. This requires strong scientific understanding, but weights can be consistently applied across the company, as a model’s credibility is independent of the exposure.
Finally, users may simply choose not to blend, and to instead occasionally run a second or third model to prompt investigations when results are materially different from the primary model.
So what to do?
Ultimately, each risk carrier must consider its personal risk appetite and resources when choosing whether to blend multiple models. No approach is definitively superior. However, all users should recognize that blending affects modeled loss integrity; in our next blog, we’ll discuss why this happens, and how these effects vary by the chosen blending methodology.…
Meghan has been with RMS since 2009 covering data quality analytics, model analytics and change management, and, since 2014, software product management. Based in California, she works with software engineers, designers, and users to build fast, user-friendly solutions for underwriting analytics, ad hoc analytics, and data import/export for applications on the RMS platform. Meghan holds a bachelor's degree in earth and planetary sciences from Harvard University.