Data Quality as an Underwriting Differentiator: Using Effective Tools for Triage
Simon ShreeveJune 11, 2021
When working together with our property and casualty (P&C) insurance clients, one trend that I have observed is how data quality has become such a critical focus area. Insurers are under increasing pressure to both build revenue and reduce expenses and they are looking for ways to evolve and differentiate. Insurers see the effective use of high-quality data as central to these objectives.
But for a P&C insurer, what sort of data or processes would make a real difference? Starting from a property cat modeling perspective, one clear differentiator comes from the use of building characteristics data, which could include construction materials, building height, or year built.
Completing the Data Picture
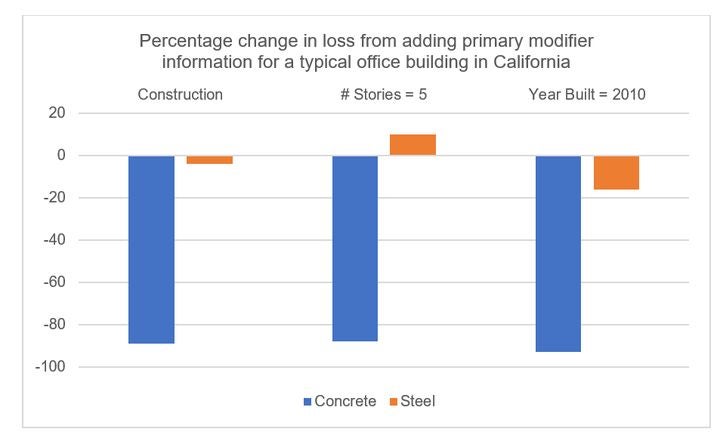
Missing or inaccurate data can significantly impact modeled loss. For instance, if we conduct sensitivity testing using the RMS® North Atlantic Hurricane Models, with regards to primary building characteristics (Figure 1), it shows large differences in location-level losses where building characteristics are not included.
Figure 1: Percentage differences in modeled insured losses for a typical office building in California when a primary modifier is added
When you aggregate these differences on an account or portfolio level, then some of the impacts might be obscured. But decision-making around overall account pricing, site limits, facultative purchasing, or other key underwriting risk management levers can be quite different when using better data.
Another area to focus on is the data that flows into modeling. Can you trust the data that has been provided? Would any missing or additional information materially impact decision-making? How can you ensure consistent data quality? Data consistency and quality are focus areas for our customers and for RMS, so we designed two solutions that can be used to address these issues: the RMS Data Quality Toolkit and the RMS ExposureSource Database (ESDB).
First, the RMS Data Quality Toolkit focuses on two areas: the completeness and the accuracy of exposure data. Or, to put it another way, the significance of what is absent and the accuracy of what is present. With regard to completeness, the toolkit considers the presence of primary characteristics and the granularity of geocoding. On accuracy, it considers exposure attributes, geocoding, policy terms and conditions, and hazard.
Second, the ESDB – part of the RMS Location Intelligence API suite – offers a database containing more than 107 million U.S. properties. The property data is derived from multiple different high-resolution data sources and passed through extensive validation, scrubbing, and scoring processes conducted by our RMS data science teams. The latest ESDB release also uses sophisticated machine-learning techniques to further increase coverage, offering a high-quality dataset that can help insurers verify, backfill, and overwrite exposure data to inform the underwriting process.
Case Study: Prioritizing Based on Materiality
There are many new data solutions on the market that purport to provide additional building attributes to help inform risk selection and pricing, but one question to ask is whether the data provided by these solutions will link back to the modeled impact from this new insight. Our recent project with a large U.S. insurer illustrated this issue, as our customer wanted to provide its underwriting team with tools to help triage submissions where there were queries due to data quality.
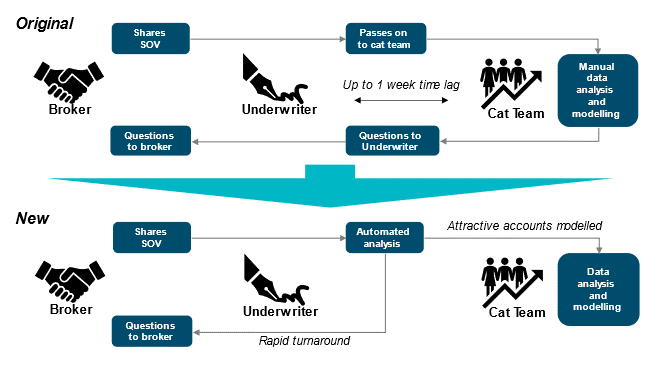
Their current triage process was proving inefficient as their underwriters were not assessing overall data quality, resulting in their cat risk team spending high levels of effort on modeling accounts that were unattractive to the business. This led to lag times of up to a week before the underwriter could interrogate the data and then go back to the broker with questions. This also had a knock-on effect in terms of submission prioritization, mispricing of accounts in both directions, and downstream impacts on portfolio data quality – and in turn, reinsurance purchasing cost.
Figure 2: Original and new triage workflows for a leading U.S. insurer
To solve this challenge, we built a workflow using RMS Location Intelligence API data calls to give underwriters the tools to triage accounts more effectively (Figure 2). We did this by showing baseline loss costs, data enhancements, and the loss cost differences post-enhancement together with sensitivity tests to demonstrate the potential impact of collecting secondary modifiers.
Combining new exposure information with loss costs allowed us to show the data quality score together with its improvement potential based on materiality and impact on modeled loss for each account. By addressing data quality at the source, underwriters were able to identify and prioritize attractive submissions and direct their cat modeling and engineering teams to look at borderline accounts in more detail. Improving the overall quality of their portfolio and providing a greater degree of pricing differentiation allowed them to avoid bad risks and compete for more attractive business.
If you would like to learn more about RMS underwriting or data quality solutions, please email sales@rms.com.
Simon is a senior manager within the Consulting team at RMS where he works with clients on risk strategy, solution design and implementation of RMS models, data, and technology solutions into their businesses.
During his six years at RMS, he has worked closely with reinsurers, primaries, reinsurance brokers and ILS managers. He is a Chartered Civil Engineer and a graduate of Bristol University with a master's in Civil Engineering. Simon is based in the RMS Hoboken office.