While the “data lake” has been around for some time, the term might still be unfamiliar to many. A data lake helps simplify analytics by bringing large, distinct sources of data together under one architecture to drive the extraction of new insights.
Nowadays, many companies maintain more than one data lake – they might have one focusing on customer- or marketing-related insights, another focusing on security and compliance, product analytics, and so on. Recently, some vendors have been using the terms “lake house” and “data mesh,” which combine elements of data lakes, data warehouses, and federated querying.
Whatever the nuanced name used, the implementation of a data lake boils down to:
Unifying various data formats and structures (including streaming, batched inputs from various file formats using structured, semistructured, and nonstructured data formatted in relational, nested, columnar formats such as CSV, JSON, Parquet, Avro, etc.)
Building a data catalog using the data in the lake (using a service such as AWS Glue, Alation, etc.)
Combining all this with an engine to query, transform, connect, enrich data, and extract new insights (using a service such as Apache Spark, Presto, etc.)
Over the past two years at RMS®, we have started putting building blocks in place for the RMS Risk Data Lake™. It builds on top of typical data lake architecture to go beyond what a “vanilla” data lake can do. In this blog, I will explore what a risk-focuseddata lake is and why it is critical for new risk insights.
Why a Risk Data Lake?
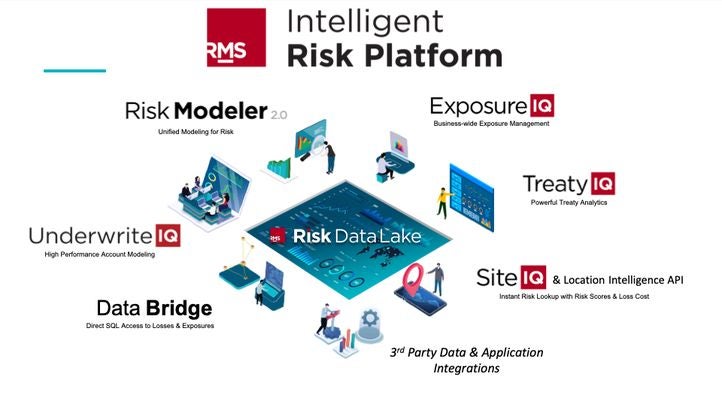
Risk is complex and connected. At RMS, we started by building a platform and applications that can help deliver exposure and loss analytics: Risk Modeler™ software and the ExposureIQ™, TreatyIQ™, SiteIQ™, and UnderwriteIQ™ applications, among others. These applications deal with known datasets and common paths.
RMS Intelligent Risk Platform
But for exploratory analyses, we need to go beyond the applications and open up ad hoc risk analytics. This requires the unification of distinct datasets that represent risk and then programmatically animating those datasets to help answer risk-related questions. I’ll touch on some of these exploratory risk analytics, but before that, let’s start with some basic definitions.
What are the essential components of the RMS Risk Data Lake, and how is it different from a vanilla data lake? The short answer is that what we are building at RMS is an “applied” data lake designed to make risk analytics simpler for data engineers, data scientists, actuaries, data analysts, and developers.
There are a few important attributes that push our Risk Data Lake over and above a vanilla data lake, including: a defined risk schema, risk data preparation utilities, risk microservices, and access to third-party risk data.
Defined Risk Schema
Wildly varying data structures offer a good starting point, and one basic premise of a data lake is its ability to work with any structure. That’s good on paper, but without some structure around the core risk objects, it will be hard to formulate risk questions. These core risk objects are just like the core data types of any programming language (string, integer, decimal, array, Boolean, and so on).
So, the first important attribute of the RMS Risk Data Lake is a data structure that brings some common definitions to these core risk objects. A risk schema also needs to be extensible to make it future proof and able to incorporate new and emerging risk data. For example, the Risk Data Lake must define a common representation of the following:
According to a paper from Google, the time and effort spent on data preparation and processing is of an order of magnitude larger than the time spent building machine learning (ML) models. Google is right. There are more than 400 risk models at RMS, so I can attest to this as well: One of the hardest parts of the process is preparing the data for the model.
The Risk Data Lake must not only define a risk schema but also convert data into this risk schema with data preparation utilities. These utilities are not very different from core data conversion functions. The Risk Data Lake provides these data preparation utilities to simplify getting risk data transformed, encoded, enriched, and summarized.
For example, the Risk Data Lake needs to provide services such as:
Encoding a roof geometry from a satellite picture into one of the Exposure Data Modules (EDM) roof geometry encodings
Reading a PDF document and converting it to a structures policy representation
Converting any exposure format from EDM, CEDE, or OED, and unifying them into a single exposure representation (for example, Risk Data Open Standard™, or RDOS)
Without risk data preparation utilities or a defined risk schema for that matter, users of a vanilla data lake would spend an inordinate amount of time reinventing them for each company and each department.
Risk Microservices
With the complexity around risk, developing a consistent financial model is important, along with a consistent method to resolve geolocation (geocoding) and aggregation functions (portfolio accumulation of exposures and losses, rolling up and grouping of modeled losses, etc.).
The Risk Data Lake, for example, needs to provide common verbs such as “roll-up-portfolio-losses,” “get-marginal-impact,” and “accumulate-risk-exposure” to enhance the productivity of risk analytics developers. These common services should support the right primitives to help get financial metrics in a consistent way, so results can be compared over time and presented with consistency.
Without these services, users of a vanilla data lake would have to rebuild each one from scratch, on their own.
Access to Third-Party Risk Data
Unlike a vanilla data lake, the Risk Data Lake needs to incorporate risk-related information in an easy-to-consume form. Users of the Risk Data Lake should have direct access to core data – including hazard; exposure attributes; environmental, social, and governance (ESG) scores; and demographic and firmographic data – from any vendor or source.
The Risk Data Lake should also have common identifiers that connect these to the core risk schema mentioned above, including exposures, portfolios, and loss estimates.
For example, the Risk Data Lake can make it simple to join different data sources together. It also needs to offer built-in identifiers (such as a unique “Building_ID” for each asset that’s a building) and simplify connecting hazard and exposure attributes (such as soil type, roof shape, occupancy, and year built) with simple lookups.
An alternative approach is the use of a unique “Company_ID” identifier that connects the building to a unique company, which would then simplify connecting “the number of people working in each building” and “list of supplier Company_IDs” that include the suppliers, and their suppliers, and so on.
Without this, the vanilla data lake user is stuck building complex data engineering pipelines that get various reference data sources into shape, and then having to deal with complex refresh logic to update them as new data comes in.
Finally, all the Risk Data Lake attributes discussed here are in addition to the regular capabilities you’d expect from any data lake, including a programmable interface, secure data access, scalable storage, data catalog, and so on.
I should also note that here at RMS, we aren’t in the business of reinventing the wheel. We are using existing data lake, lake house, and data mesh capabilities ourselves. However, moving from a vanilla data lake to your own Risk Data Lake takes a lot of work. We want to ensure that you do not need to build your own capabilities from the ground up for programmable risk insights – so you get an applied data lake with risk analytics that are simple and accessible.
What Can You Do with a Risk Data Lake?
Space and time won’t permit an exhaustive discussion of this important topic. But let’s cover three insurance use cases.
Tuning Risk Models for Risk Strategy
Many of our clients have customized risk strategies, which are their “secret sauce.” A critical aspect of that risk strategy comes from tuning, customizing, and blending risk models. Applications on the RMS Intelligent Risk Platform™, such as Risk Modeler, provide ways to apply customizations – but developing thecustomizations is not easy to do.
How do you know what level of change to apply to “event rates” in a model? How about “loss frequencies”? In which regions should you apply this change? Or should these rates change based on the exposure type? How about blending multiple models? How should each blended model influence and contribute to the blended model output? These are complex questions.
Applications take the input once you have identified the customizations. But the work that’s needed is not served by applications themselves: creating the exact tuning parameters, testing those changes, and modifying them over time as models evolve. The RMS Risk Data Lake can help with these explorations and determine what kind of tuning and blending logic you need for custom models.
Combining ESG Risk into Underwriting
In this new era, we know that sustainable finance is a key evaluation metric for financial services and insurance companies. However, (re)insurers also know designing a strategy around ESG risks isn’t simple.
(Re)insurance companies need to decide:
The ESG risk for each insured entity
How to help an insured entity transition to increased sustainability
How to price each insured in relation to these sustainability improvements
Designing that strategy requires a deep understanding of not only physical risk but also ESG risks and sustainability metrics balanced with physical risk metrics. Developing an underwriting strategy that prices for a combination of physical and ESG risks require ad hoc exploration to test scenarios and returns on these risks.
This is where the Risk Data Lake can provide the surface for this exploration – to bring the datasets for physical and ESG risk together onto one surface and allow for ad hoc querying of these metrics.
Compiling “Golden” Underwriting Data
We know how important data is to touchless underwriting. Data elements such as hazard, exposure data, and risk scoring help automate the underwriting process. However, similar to models, different vendors have varying data quality for each region. So, compiling a single “gold” copy of your underwriting dataset to help price transactions can be hard.
How do you know which vendor has the best data in North Carolina versus California for rating each house’s “foundation type” in your touchless underwriting? What if one vendor’s data for “roof age” across Europe looks promising but another vendor has better coverage on “first-floor height”?
How do you decide which vendor, which region, and for which attributes? The Risk Data Lake can help compare risk model loss estimates and actual losses to the data from these vendors and help create your blended “gold” copy of the underwriting data.
Finally, while this list of what you can do with a risk data lake is nowhere near complete, it provides a few examples of how new insights and better performance can be achieved in risk trading across (re)insurance and financial services organizations.
Today at RMS, the Risk Data Lake is still under development within the RMS Intelligent Risk Platform. If you’d like to learn more about our platform, please visit rms.com. If you’d like to explore the RMS Risk Data Lake and partner with us on your use case, please reach out to me.
Managing Director - Head of Product for Moody's RMS
Cihan is the Managing Director - Head of Moody's RMS Product, responsible for product management across the full suite of Moody's RMS models and risk management tools. He has extensive experience in leading product management for innovative machine learning and big data analytics solutions at Fortune 500 companies over the last 20 years.
As a former Vice President of Product at Databricks and Redis Labs, Cihan developed the product strategy and road map for open-source technologies such as Apache Spark and Redis and respective enterprise offerings in the public and private cloud platforms.
Cihan also worked on products at Microsoft, Couchbase, and Twitter, where he focused on on-premises and cloud offerings in the data and analytics space. At Microsoft, Cihan focused on the incubation of the Azure Cloud Platform in its early days and the SQL Server product line, both of which have grown into multi-billion-dollar businesses for Microsoft.
Cihan holds several patents in the data management and analytics space, and he has a master’s degree in database systems and a bachelor’s degree in computer engineering.