In the dynamic world of catastrophe modeling, where uncertainties abound, one question has always lingered – can we ever be certain about the uncertainties of catastrophe risk?
This question has been at the heart of our industry for years, pushing Moody’s to explore new methodologies and approaches to move closer to answering this question with a ‘yes.’
Our innovative high-definition (HD) modeling brings us significantly closer to answering in the affirmative. It harnesses the capabilities of Monte Carlo simulation – which uses random sampling to estimate complex outcomes and analyze uncertainty, to provide a unique perspective on quantifying the risk in catastrophe modeling.
Rather than rewriting the playbook, HD models allow us to explore the concept of ‘convergence.’
Model convergence occurs when the distribution of simulated losses stops changing significantly with additional simulations. This indicates that the model has captured the essential features of the risk being modeled and that running more simulations would not provide any additional insight.
This may seem a bit technical, but convergence is an essential concept that should inform how we manage modeling uncertainty and its downstream impact on a wide range of workflows from underwriting to capital management.
The additional uncertainty created from working with unconverged model output can lead to inaccurate price loadings, illogical levels of risk capital, and inadequately structured ceded reinsurance programs – each of which can threaten business goals and, ultimately, solvency.
Without understanding or quantifying uncertainty it can result in price loading, increases to risk capital, or how much reinsurance is purchased to ensure the solvency of your business.
In this blog, I’ll delve into the meaning of convergence and use examples to help show how it offers a new lens into our understanding of catastrophe risk.
Understanding Model Convergence: A Case Study on Comparing Height
Have you ever wondered whether you are tall? It might seem like a simple question, but its answer hinges on context – a context that parallels the concept of convergence in catastrophe modeling.
As an actuary, I strive to use a data-driven approach to answer all my questions concerning life. For instance, simply Googling the average global height for males and comparing it to mine is insufficient. I want to understand the entire height distribution and where I fit in.
To do so, I built a model based on a random sampling of individuals across the globe. In my first sample, I picked one person from ten cities and measured their heights against mine.
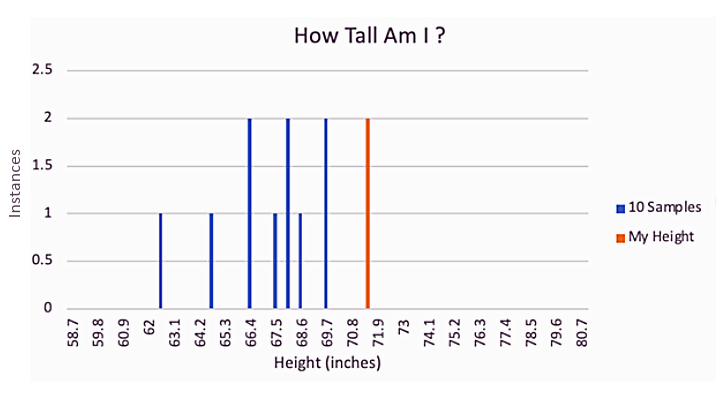
At first glance, this limited sample might lead us to a hasty conclusion: I am the tallest person in the world.
This initial assessment hardly paints a complete or accurate picture. I don’t think any actuary worth his or her salt would be willing to make this conclusion based on such a small sample size. To gain a more comprehensive view, I’ll expand the sample size from ten to one hundred cities.
This second sample with a larger dataset offers a better perspective, and I can begin to see a distribution of height that makes more sense to me.
I have moved from being in the one-hundredth percentile in height to the 79.5th percentile. Given this change in how tall I am against my sample, I might start to question the selection criteria and wonder whether the first or this second sample was truly representative of the entire population.
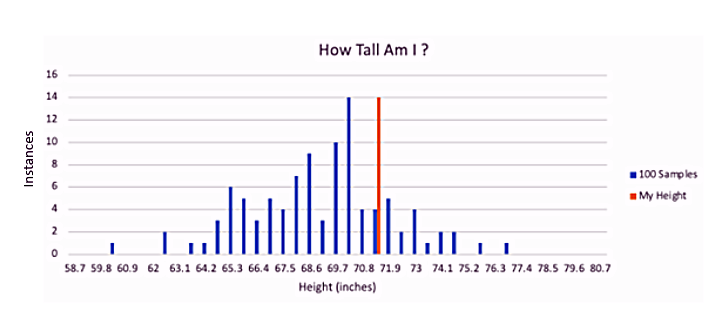
Taking a deeper dive, we can improve our data even further with a third sample comparing my height to ten people from each of those 100 cities.
This diverse, expansive sample provides a much clearer, more representative distribution of heights.
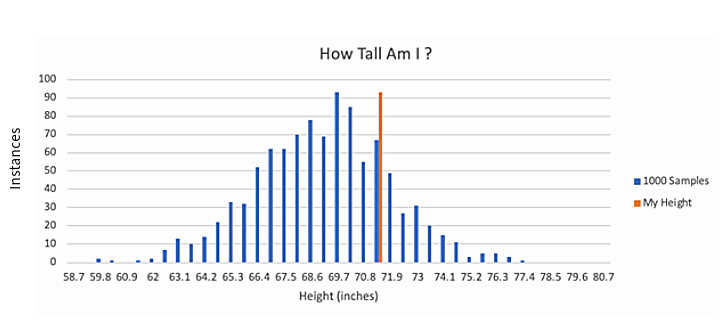
Our evaluation of whether I am or not tall is now grounded in a broader, more reliable context.
When I expanded the third sample to a thousand people, the percentile of my height only changed 1.13 percent or from the 79.5th percentile to the 78.6th.
Now, here’s where convergence comes into play.
If we expand our sample from ten people in 100 cities to five or even 10 people in 1,000 cities, how better of an idea of how tall I am with the rest of the population would I have?
|
Samples
|
My Height
(percentile)
|
Percent change
|
Average Sample Height
|
Percent change
|
|
10
|
100%
|
N/A
|
67.42676
|
N/A
|
|
100
|
79.50%
|
20.50%
|
69.26411
|
-2.72%
|
|
1,000
|
78.60%
|
1.13%
|
69.3303
|
-0.10%
|
|
5,000
|
78.50%
|
0.13%
|
69.2930
|
0.05%
|
|
10,000
|
78.00%
|
0.64%
|
69.2935
|
0.00%
|
When I increased samples from ten to one hundred, a large change in my estimated percentile was observed. This suggests that my simulated data may not have captured the true distribution of global height.
Expanding from one hundred to one thousand samples, I began to see my estimate converge as the change in the percentile estimate reduced greatly.
By the time I expanded to five thousand samples, adding one more for 5,001 or even doubling to ten thousand did not make a material difference in my understanding of how tall I am compared to the rest of the global population.
Expanding from one hundred to one thousand samples, I began to see my estimate converge as the change in the percentile estimate reduced greatly.
It’s worth mentioning that it is difficult to determine when we’ve reached a converged view of my height percentile.
Note, for instance, that the percent change between 5,000 and 10,000 samples is greater than the percent change from 1,000 to 5,000. On the surface, this may seem like the estimate is unstable.
However, given the scale of difference here I would tend to view this as noise and the nature of random sampling (or random number generation in this case.)
Ultimately, our sampling has provided a data-driven and mathematically sound approach for me to make an informed conclusion, and using a bit of professional judgment, I feel confident saying that I’m in the 78th to 79th percentile of global height.
Applying Convergence to Catastrophe Modeling and Risk Decision-Making
Firms with a strong understanding of convergence within their catastrophe models are better equipped to make informed choices regarding a risk's technical price and volatility.
This understanding enhances decision-making in various areas such as underwriting, portfolio steering, and capital management.
Instead of posing a simple question as ‘Am I tall?’ (as I did in the mental exercise), I can start to explore the volatility of a single risk or a portfolio encompassing thousands of risks.
Questions include:
- Does this risk have an appropriate margin embedded in its price? or
- Does this new account nudge the risk profile of my portfolio in the right direction?
High-definition (HD) models help achieve convergence but also offer greater confidence in your risk assessments because of the convergence, something not offered with other Monte Carlo simulation-based models.
Unlike other vendor models, HD models offer two unique differentiators – the largest event catalog and user-defined sampling. This flexibility allows you to choose the number of periods to run against your portfolio (analogous to exploring the cities around the world for the height experiment) as well as define how many samples of each period should be run (analogous to the people selected within each city), giving you the power and control to explore convergence within the context of your firm’s risk tolerance.
So, what’s the benefit? It ensures that your risk assessment is reliable and stable. With HD models, you can customize the number of times you run each event in your catalog, allowing you to fine-tune your analysis and reach converged results more confidently.
In essence, HD models empower you to make informed decisions by providing a more precise and reliable understanding of your losses in different risk management contexts.
To find out more about HD modeling, click here.





